
There’s been a lot of talk lately about how SEO is evolving—or more accurately, being replaced—by something fundamentally different: Generative Engine Optimization, or GEO. At the core of this shift is the need for a new methodology to track, interpret, and categorize.
One of the most urgent problems we now face is that we’re still trying to interpret generative engines using outdated SEO logic. We’re asking the wrong questions and misreading the limited data we do have.
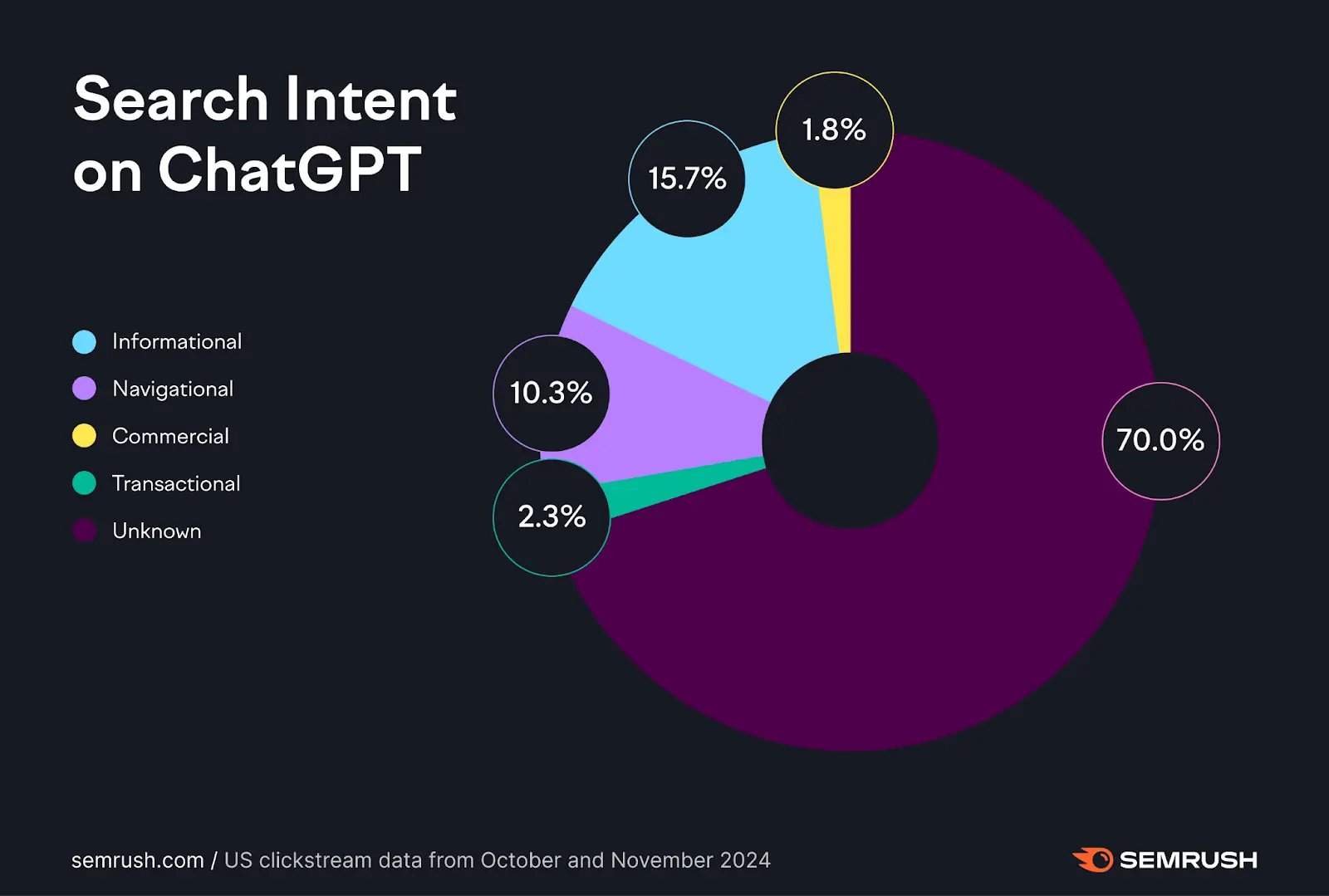
In this article, we do a granular breakdown of Semrush’s Investigating ChatGPT Search: Insights from 80 Million Clickstream Records study to address the lingering problem of classifying and interpreting this type of data. In the industry—if you read at all—you’re probably familiar with the “70% unknown intents” figure that’s often cited. Here, we directly address how this type of data should be categorized and introduce some of the terminology our industry needs to adopt.
To their credit, Semrush asked the right questions. They examined how people use ChatGPT, what types of queries are being made, and what behaviors are emerging inside generative interfaces. The result is one of the most important studies our industry has seen in years. And it revealed something many of us—myself included—needed to see laid out clearly: traditional SEO frameworks do not map cleanly onto how conversational interfaces like ChatGPT function.
In SEO, we adopted terms like “search intent” because those terms were defined by the search engines themselves. Today, we’re facing a similar inflection point. A new technology has arrived, and just as we did in SEO’s early days, we must adopt its native terminology if we want to understand what we’re optimizing for—and how to structure and interpret our data.
That vocabulary includes terms like utterances, turns, multi-turn conversations, and utterance classification. These are foundational to how conversational interfaces using LLMs operate. Yet they’re still largely—if not completely—absent from mainstream SEO/GEO literature.
In this article, we revisit the Semrush study with fresh eyes—through the lens of GEO—and explore how this new system should be interpreted. Along the way, we introduce essential concepts and context to help guide our industry toward a more accurate, generative-first framework.
We also challenge the current paradigm of tracking single prompts, making the case that the future of GEO relies on synthetic data and simulations—while touching on some systems we’re building at Flying V Group.
How Search Intent Could Not Label 70% of Prompts and How This Could Have Been Solved Using Utterance Classification
The most glaring issue—and the single most illustrative point of why SEO can’t just be mapped onto LLMs—is that Semrush relied on search intent methods of classification to try to map user utterances. Mind you, this is not a criticism, the study was released over 3 months ago and Semrush humbly called it out, saying we need think about these things in a different way and that’s what we’re doing here. So it’s actually kudos to Semrush for calling this out and this is not a slander, simply a re-examination of what actually was an amazing study and what it teaches about mapping SEO to GEO.
With that said, the study did note that 70% of the data could not be labelled using classical search intents. This illustrates how we won’t be able to classify this new era of LLM data using search engine classification. These are conversation interfaces and they consist of utterances and turns, equating to multi-turn conversations. That’s what we are ACTUALLY optimizing for in GEO.
Let’s define these terms below:
Any string of text “uttered” by the LLM or user is referred to as an utterance. There are two types:
1. User Utterances (strings of text “uttered” by the user)
2. LLM Utterances (strings of text “uttered” by the LLM)
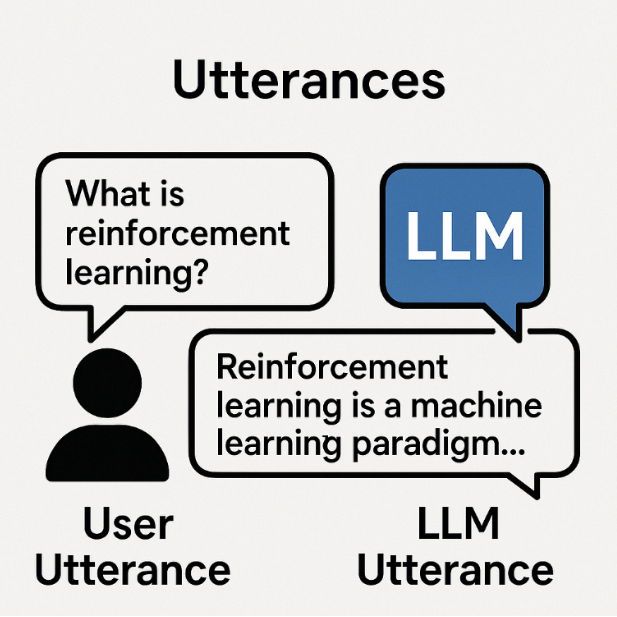
An utterance from a user with an utterance from the LLM equates to a turn:
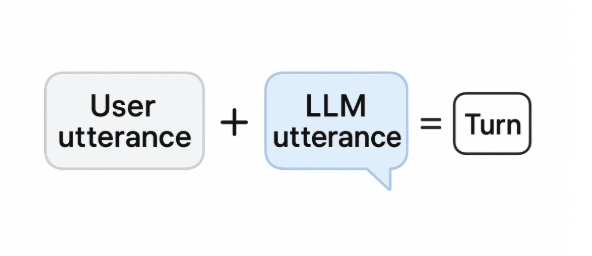
The full picture looks like this:
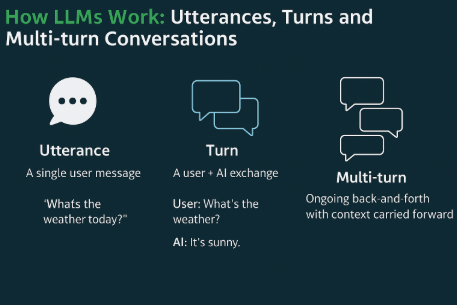
Ultimately, these prompts should have been classified using what is called utterance classification.. Had that been done, the insights would have been far more valuable. Again, not a slander, great study, but the insights would have allowed us to contextualise this data a lot better.
Utterance classification is a fundamental technique used in every serious chat-bot system. It provides much richer insights than traditional search intent models. Even at a broad level, it offers classifications such as “opinion requesting” and “clarification seeking,” which are more nuanced and descriptive than standard search intents.

They can become highly contextual and nuanced enabling a deeper understanding of user journeys and multi-turn conversations:

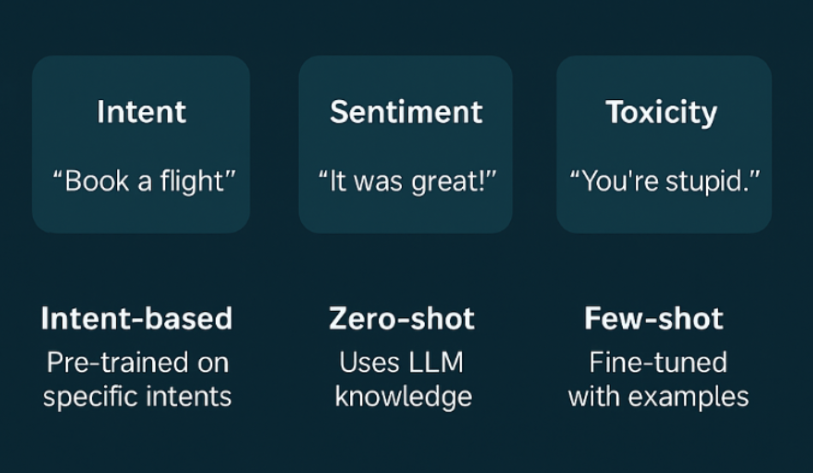
Utterance classifications at a basic level consist of three approaches: zero-shot classification, curated intent classification, and few shot classification classification.
Zero-shot classification applies when there’s no explicit training data or few examples, allowing the model to predict the category of an utterance on the fly. Curated Intent classification identifies what the users pre-defined categories, while hybrid classification combines elements of both:
Utterance classification isn’t new. It has been around since the 1990s and played a central role in early voice search systems. Ironically, it’s the foundation of voice search—something the SEO industry frequently discusses.
If utterance classification had been applied to this dataset, it would have opened the door to far more granular insights. Every prompt could have been labeled and categorized—not just by broad topic, but by specific user intent, request type, and even industry vertical. We could have seen real patterns emerge in how people interact with LLMs, mapped against the types of instructions they give and the outcomes they’re seeking.
Instead, by applying traditional SEO classifications to a technology that doesn’t operate like a search engine, the study produced one particularly striking result: a chart showing that over 70% of prompts were left unclassified. You can view that chart here. That moment makes something very clear—there’s a gap between the methods we’re using and the systems we’re trying to understand. But with that said, Semrush was humble and called for different ways of classifying this new data, that new way needs to be utterance classifcation.
Had utterance classification been applied, the data narrative could have been significantly richer—yielding insights that help marketers, technologists, and content creators understand what users truly want from generative systems. The opportunity is still there, and with the right framing, we can turn this into a major leap forward for the entire industry if we adopt this approach.
The Study Missed The Significant Role of Adaptive Retrieval and Its Role in What Drives ChatGPT Citations
The article focused on which prompts in ChatGPT’s primary interface triggered citations, but didn’t mention adaptive retrieval at all.
That’s the fundamental mechanism here: adaptive retrieval is what decides whether to augment a response with external information.
Citations in the primary interface of ChatGPT comes from adaptive retrieval scoring:

While we’re here, let’s take a moment to explore Adaptive Retrieval and how it works. To the best of my knowledge (though I could be wrong), RAGate was the first research paper to gain mainstream attention for addressing adaptive retrieval. If you’re interested, you can read the original paper here.
At its core, a simplified version of RAGate functions as a binary classifier that determines when an LLM should or should not augment its response. The more detailed explanation is that RAGate uses a gating function to decide when to trigger augmentation. It includes three variants and incorporates a combination of a trained BERT ranker and TF-IDF as rankers and retrievers.
There’s an even more technical breakdown available, but we’ll skip that for now. Below is the original framework:
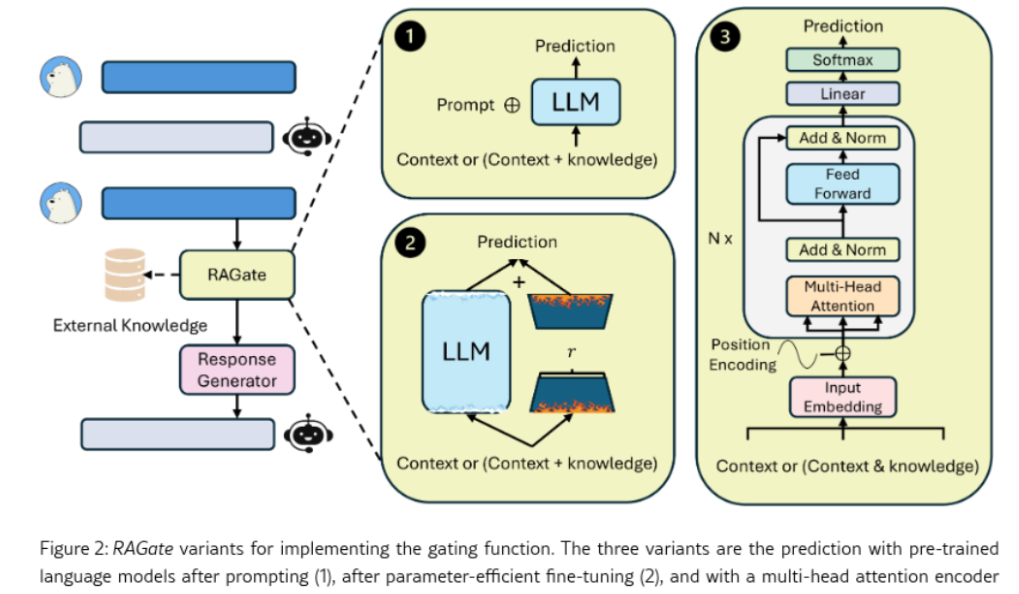
The answers were grounded using the KETOD dataset. While the process may seem complex at first, the core idea is simple: these classifiers are what trigger augmentation. It is essential for companies to understand them and apply them correctly.
Semrush made a great observation here, but contextualising this observation through the lens of SEO is that it leads to broad generalisations. People start saying things like “news triggers results,” or “trending topics perform well, so we should invest there,” and “informational content does not, so we shouldn’t invest in it.”
These generalizations are harmful. Running observational studies without understanding the underlying context of what you are observing, in my opinion, can lead to missed opportunities and potentially wrong narratives.
There is no need to guess or rely on surface-level observations. Dynamic and adaptive classifiers already exist. For example, the Gemini 2.0 API offers access to dynamic thresholds:
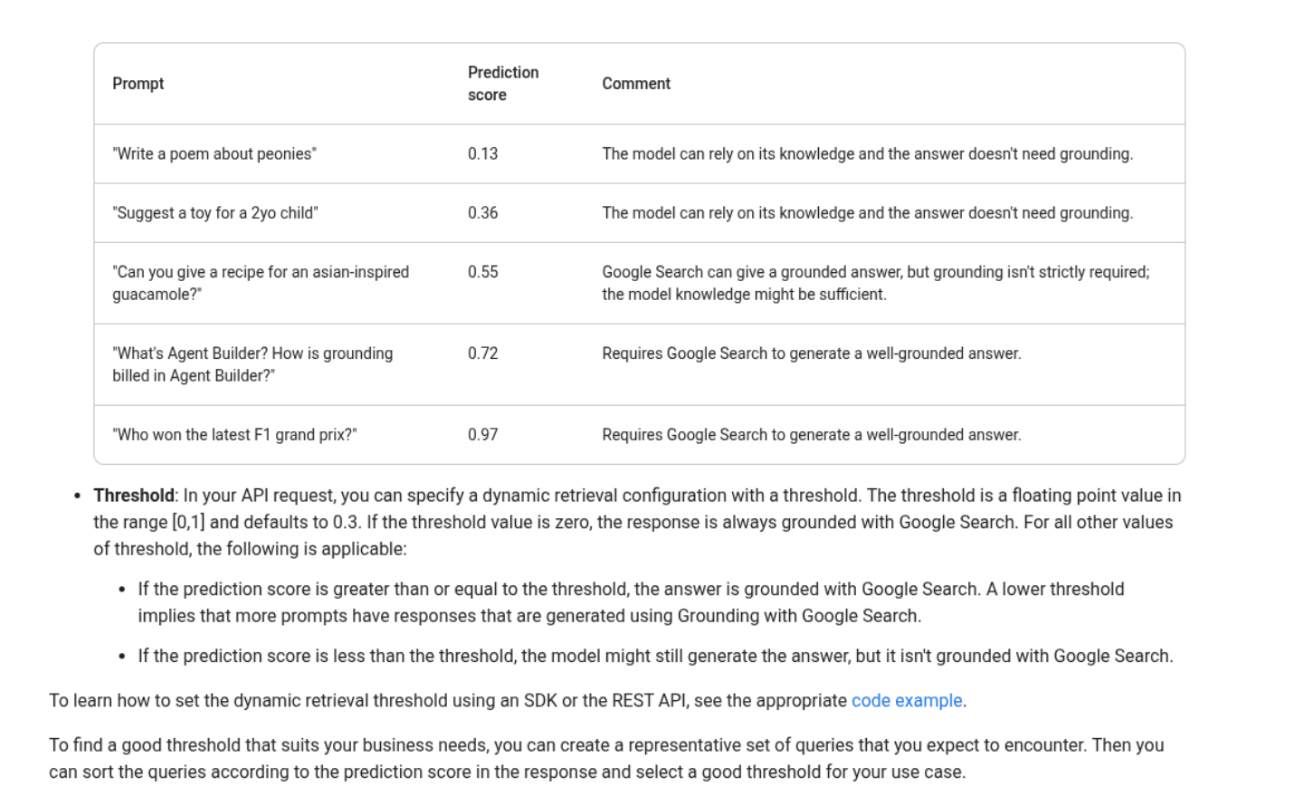
These thresholds can be applied to even basic keywords to give brands an unambiguous guide as to which types of keywords WILL and WILL NOT result in getting cited by an LLM.
Though this was an amaxzing study, it teaches us the definition of what we observing already exists and is something we should seek out before we begin to try and describe it.
Mapping Singular Intents to Long Prompts, Multiple Intents Should Have Been Talked About, Along With Multi-hop Retrieval/RAG
Am I surprised that Semrush didn’t mention multi-hop retrieval in the context of this study? Not at all. The only time I’ve seen the community even begin to touch on the topic was when analyzing the patent related to AI and fanout queries.
Here’s the reality: multi-retrieval techniques have existed since before 2022. Google is not ahead in LLM development. Their strength lies in information retrieval, not in large language models. While fanout queries are distinct, they’re conceptually similar to multi-hop retrieval and clearly influenced by recent advances in the field.
This even builds off Google’s own internal principle known as “Query Deserves Diversity.”
This principle reflects Google’s long-standing understanding that a single query can carry multiple intents. Why it took the broader industry nearly two decades to catch up remains unclear.
Even more concerning is that longer prompts, which almost always contain multiple intents and instructions (as recognized by utterance classification), will continue to be overlooked if we rely on classical search intents.
Had multi-hop concepts been taken into account and applied properly, we could have labeled the dataset with a high degree of accuracy. We could have identified which prompts likely triggered multi-hop retrieval and disambiguated the long prompts and the intent that laid behind them.
Multi-hop RAG and retrieval methods are designed to handle this kind of complexity. They solve the challenge of deeper research by performing multiple retrievals based on a single prompt, offering a more comprehensive response. Below is a simplified visual of what multi-hop retrieval looks like when applied to a complex prompt with multiple intents:
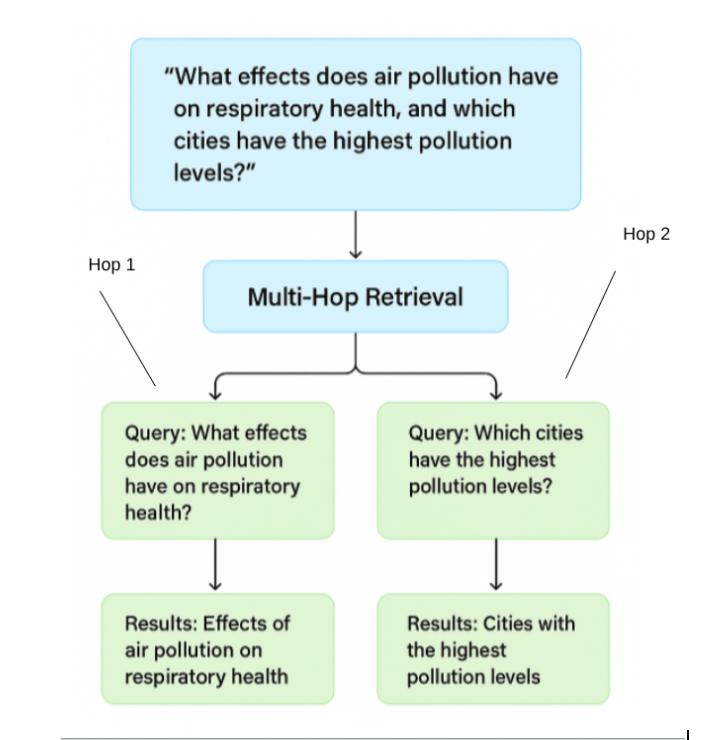
The other application is to a more singular topic in which Chain-of-Thought reasoning, at least, in more sophisticated systems. This is what CoT RAG is all about.
From Google’s release video in relation to AI mode we can quite literally see the multi-hops taking place coupled with Chain of Thought reasoning to accomplish tasks:
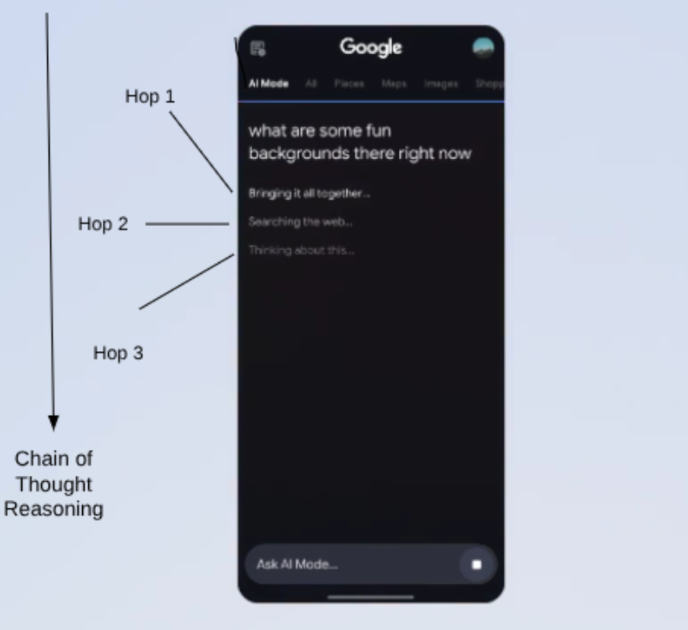
Right now, Google is taking established concepts and terminology from the research community, rebranding them, and filing patents.
Our community then analyzes these patents, adopts the new terminology, and in doing so, creates competing language with the terminology already used in the LLM community. This fragmentation makes it harder for the GEO community to reach a shared understanding.
We’ve seen this before. What the research community calls adaptive retrieval, Google now refers to as dynamic retrieval. In general, I encourage everyone in the field to study the original research papers that precede consumer-facing implementations. This helps us anticipate what’s coming and better understand how these commercial versions differ from the original concepts.
In the case of Semrush, had they not tried to force single-intent frameworks onto multi-intent prompts, they could have potentially have:
The Biggest Learning of All: No Mention of Basic LLM Vocabulary
Perhaps the most concerning issue is the lack of adoption of proper terminology throughout the industry. When search engines emerged, we adopted the concept of search intents and for good reason. The search engines themselves defined those terms.
We clearly need to take the same approach with LLMs.
And the truth is, the vocabulary isn’t that difficult.
- Utterances = a string of text from an LLM or User
- A turn is an utterance + an utterance
- Multiple turns = multi-turn conversations
Is there a single mention of utterances in Semrush’s literature? Nope:
Has Ahrefs mentioned utterances? Nope:
My Final Verdict: The Industry Needs to Make a Big Shift, Ideally Fast
Will I catch some flack for writing this? Probably. But I’m okay with that—because this conversation is necessary for the evolution of our industry.
Semrush deserves real credit for taking the initiative to investigate how users interact with generative engines. Their study brought attention to a dataset that few others could access, and it opened the door for important questions about how we measure and understand behavior in generative environments.
That said, I believe it’s time for leading tools and publications to re-evaluate their methodologies and begin adopting the foundational language that underpins how large language models actually work.
Imagine the added depth this study could have reached if utterance classification had been applied. The insights could have been transformative—potentially the most impactful contribution to this emerging field to date.
The dataset itself was excellent. But the analysis, while a valuable first step, missed an opportunity to fully align with how generative engines function. That’s not a criticism—it’s a call to action.
I genuinely hope Semrush revisits the data through the lens of conversational structure, applies updated classification frameworks, and considers releasing a follow-up. It would not only strengthen their leadership in this space but also set a new standard for how we approach GEO moving forward.
Some The Advanced Methods and Tools We Are Building at Flying V Group
At Flying V Group, we’re not just following trends — we’re building the next generation of GEO methodologies from the ground up. Below are some of the advanced methods and tools we’re developing to push the boundaries of what’s possible in this space.
Identifying Keywords That Will Result in Citations With a High-Degree of Confidence
The industry can use Google’s grounding with Gemini confidence intervals to batch identify which queries (query rewrites) will be served content to LLMs.
This enables us to determine with high confidence which queries and content will result in citations and be pulled from LLMs on a macro scale.
Adaptive retrieval logic decides whether ChatGPT will pull external documents. These adaptive thresholds can be applied to large keyword datasets to identify which types of keywords will generate citations and which will not.
This gives companies a clear guide on what content they should and should not invest in, with a high degree of confidence. The underlying logic is demonstrated in Google’s dynamic threshold example below:
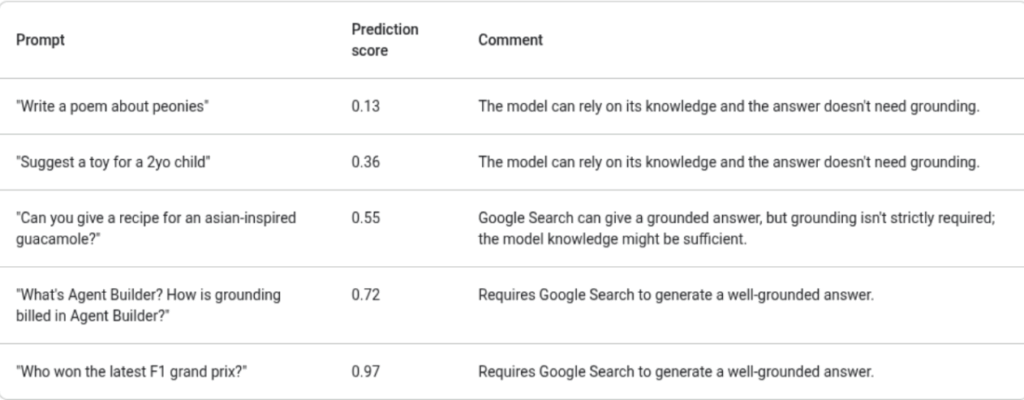
Simulating and Mapping Multi-conversation Based on Persona
We’ve been able to develop an early tool which allows us with some degree of efficacy to simulate full multi-turn conversations based on persona, below is a sneak peak:

Identifying Low-competition Topics by Applying Grounding Scores
Identifying which content will be cited by LLMs is important, but finding low-competition keywords is equally valuable.
By combining dynamic thresholds with grounding scores, we can determine both the types of content likely to be cited and pinpoint low-hanging opportunities.
Grounding scores measure how much an answer improves through retrieval. A low grounding score suggests that retrieval had little impact on the answer. While there can be various reasons for this, one key indicator is content scarcity, which means there is limited existing content on the topic and signals low competition.

Identifying Important Citations Through Thousands of Conversational Simulations by ICP
While we’re proud to have achieved the ability to simulate multi-turn conversations based on persona, a recent discussion with a highly knowledgeable prospective client made it clear that each persona can follow multiple conversational paths.
So how do we identify which content is most likely to be shown to a given persona? Our hypothesis is that we can solve this by generating thousands of permutations by ICP, then analyzing which citations are pulled most frequently across those variations. Below is the conceptual logic:
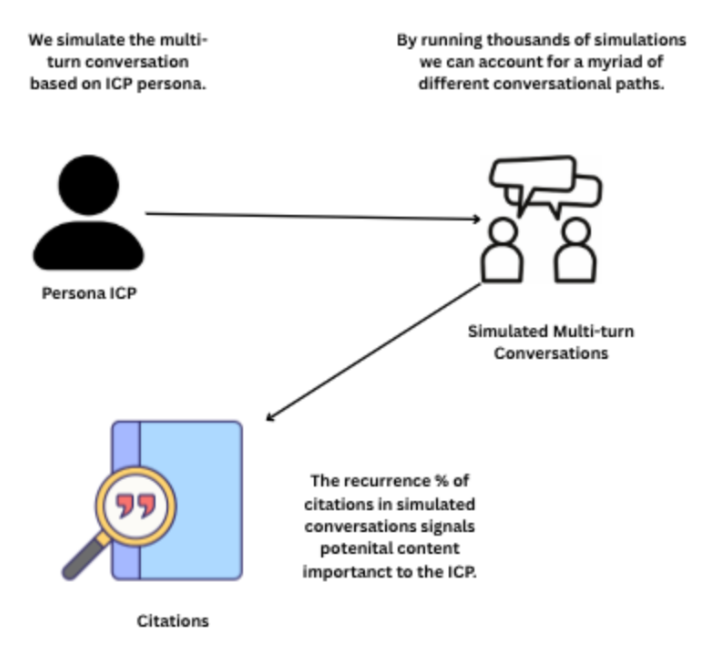
We’re early days with this, but reckon it’ll be worked into our approach within the next 30-days.
Deep Research and User Behavior
Though deep research is the frontier, optimising for this is largely based on understanding CoT RAG coupled with ToT reasoning. Chain-of-thought reasoning is a progressive form of reasoning while ToT is a recursive form of logic which allows the LLM to reverse its path and pick the best path to achieve the best outcome.
CoT RAG coupled with ToT and a large context window is what enables sophisticated research assistance. Our understanding of how this works is quite strong and we’re working on some pretty cool approaches.
Influencing LLMs Through Brute Force Optimisation
Another area we’re experimenting with is allowing AI to make tweaks to internal web content using the AI to judge the changed LLM outputs from retrieval. Surprisingly, we can actually index and iterate pretty quickly, this logic allows brands to just sit back and have AI optimize content to influence LLM outputs on autopilot.
In Conclusion
As I close this piece, I want to make something clear: I wrote this not to tear down Semrush or to fuel more division in our already fragmented marketing world. I wrote it because I care deeply about the future of this industry, a future I believe is being stunted by misunderstandings, misapplications, and a refusal to evolve.
I am not claiming to have all the answers, but one thing is certain: Generative Engine Optimization is not SEO. It demands new thinking, new techniques, and, above all, a willingness to question old narratives. What I see across the board, SEOs clinging to dated frameworks while powerful multi-turn conversations upend everything around them.
SEO gave me, a community college dropout, a path. I have seen it give thousands of others the same. But if we want to honor that gift, we have to let go of what is comfortable and embrace what is next. That means understanding utterances, adaptive retrieval, multi-hop logic, even if it feels like we are starting over.
Flying V Group is trying to do that. We are not perfect, but we are doing the hard work to map this new terrain. My hope is that others will join us in rethinking the very foundations of search, marketing, and how we engage with the world’s most powerful AI systems.
Let’s move beyond the old playbook. Let’s build a new one, together.




{kind=link}