
For nearly three decades, the rules of SEO content were straightforward: write original content based on keyword metrics, and Google will (depending on a number of variables) likely crawl your site and make your information available.
As digital marketers we optimized for machines that read everything and understood nothing. However, since the onset of AI-search, this has fundamentally changed. Traditional search has been replaced by LLMs that can answer questions by default. Systems like Gemini and ChatGPT answer from their own knowledge by default, and reach for your page only when confidence in that store of parametric knowledge falls below a certain threshold. Researchers call this mode of search “adaptive retrieval” and it functions as a trigger for search. The trigger varies per search, ask who wrote Crime and Punishment and Gemini might answer instantly because the question has been settled for two centuries.
However, ask for the tallest building in Turkey, or the most recent price of oil, and it searches because it cannot be confident that its training data reflects the most current and reliable answer. The issue is that thus far almost no one has tried to measure the viability of content against the one audience that increasingly decides visibility, the model itself.
At Flying V Group (FVG), we partnered closely with our sister company GEO Genius, founded by leading members of our team here at FVG, and developed the Commodity Content Score as part of our MCP (Model Context Protocol) toolkit as a metric to estimate how much of a page an LLM could generate without any human help, separating commodity information from novel information. It turns a vague instruction, “be original,” into something that a publisher can measure.
The goal in creating this metric was straightforward: create a viable means to help publishers understand how much of their content can already be generated by large language models (LLMs) and how much of it provides genuinely novel information.
We believe this distinction may be important for two reasons.
First, content containing information AI systems do not already know may be more likely to earn visibility through retrieval systems such as ChatGPT and Gemini.
Second, content that contributes new knowledge may be more likely to influence future training datasets and model outputs.
Both Google and leading AI companies consistently emphasize the importance of creating unique, original content. While that recommendation is widely repeated, there has been surprisingly little work focused on measuring uniqueness through the lens of what a model already knows.
Our Definition of Commodity Content
Commodity content is information that a model can already generate without human assistance and timely, real world insights (ie. “how to tie a shoe”).
Conversely, non-commodity content consists of information, observations, expertise, data, experiences, or insights that are not already represented within the model’s existing knowledge (i.e. “the tallest building in Turkey” or “what is the price of oil today”).
As search increasingly evolves into AI-mediated retrieval, understanding the difference between what models know and what content contributes may become one of the most important concepts in Generative Engine Optimization (GEO).

The Relationship Between Adaptive Retrieval, Model Training, and Commodity Content
At a high level, the model assesses its confidence in its own parametric knowledge—the information encoded within its weights during training.
When confidence is sufficiently high, a model may answer directly from memory. In the example below for the question “how to tie my shoe” provides a fast answer because how to tie your is generic information it already knows:
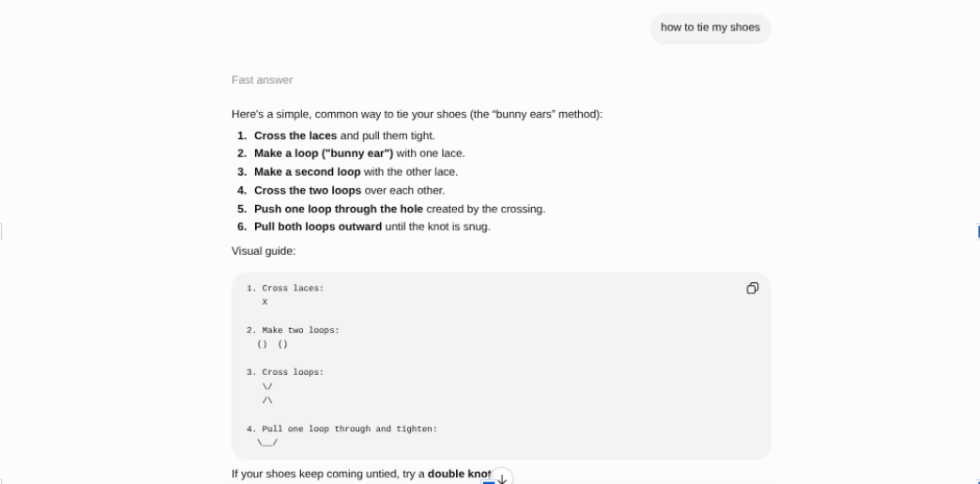
When confidence is lower, retrieval systems may be activated to supplement the model’s existing knowledge with external information.
For example, when we ask the question what is the tallest building in the world as of today the model searches because it is not confident enough to answer because it does not have specific information pertaining to today (maybe a taller building was built since its last training update), so the model searches:

While retrieval decisions are influenced by multiple factors including freshness, grounding, verification, and hallucination prevention, a model’s existing knowledge remains one of the primary inputs influencing whether retrieval is beneficial.
This creates a potentially important relationship between commodity content and AI visibility.
If retrieval is frequently triggered when models lack confidence or lack sufficient knowledge to answer a query, then content containing information absent from model knowledge should theoretically provide more value than content that merely repeats information the model already knows.
In practical terms:
- High commodity content contains information already represented within model knowledge.
- Low commodity content contains information the model does not already possess.
- Information the model does not possess is more likely to provide value during retrieval.
The same logic extends beyond retrieval into model training.
Modern training pipelines are designed to improve model capabilities, increase knowledge coverage, and expand understanding of the world. While training datasets are selected based on numerous quality signals, research consistently shows that data quality, information density, diversity, and knowledge contribution are important considerations.
Content that simply restates information already present across millions of documents contributes relatively little additional knowledge.
Content containing proprietary research, original data, first-hand expertise, unique observations, and novel insights contributes information that may not already exist within the model’s training distribution.
For that reason, we hypothesize that lower commodity content may have a higher likelihood of influencing future training datasets because it contributes net-new knowledge rather than repeating existing knowledge.
Study Design: How We Performed Our Analysis
To evaluate the Commodity Content Score, we analyzed content from four widely recognized Fortune 500 publishers:
Using Semrush AI Traffic data from May, we collected several hundred URLs across these publishers. Service pages, product pages, and commercial landing pages were excluded to reduce noise and maintain consistency across the dataset.
Furthermore, approximately 2% of URLs failed during the scraping process and were removed from the final analysis.
Although the resulting sample size consisted of only several hundred URLs, multiple analyses achieved statistical significance despite the relatively modest dataset.
A Simple Litmus Test: Does the Score Track Model Cutoff Dates?
Before testing whether commodity content influences AI visibility, we had to confirm the score measures what it claims to. The cleanest check compares pages published before and after a model’s training cutoff. If the Commodity Content Score genuinely captures knowledge overlap, pre-cutoff pages should score high, since the model likely trained on that material, and post-cutoff pages should score low, since the model could not have seen them.
The results were striking.
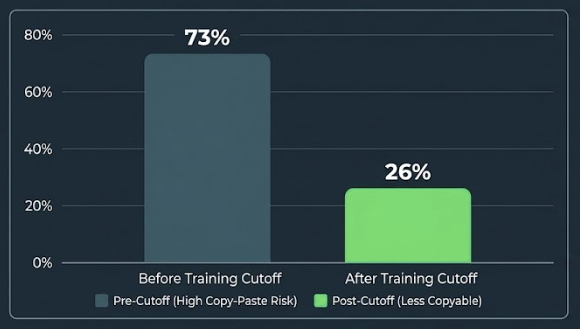
Pages published before the cutoff date received an average Commodity Content Score of 72.6%.
Pages published after the cutoff date received an average Commodity Content Score of 26.1%.
This represents a 178% relative increase in commodity content among pages published before the cutoff date, with a 95% confidence interval ranging from 142% to 224%.
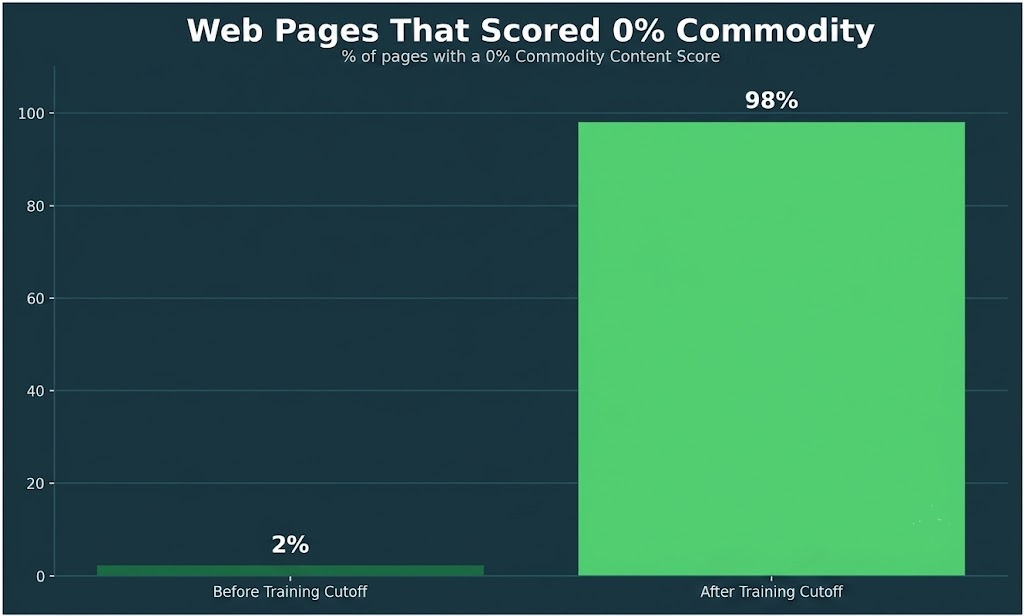
The tail of the distribution told the same story. Nearly every page scoring 0% commodity content, meaning the model recognized none of the information on the page, was published after GPT-5’s training cutoff. A score that behaves this precisely against a known boundary is measuring the thing it was built to measure: how much of a page’s content a model can already reproduce on its own.
Examining The Relationship Between Commodity Content Scores and AI Visibility
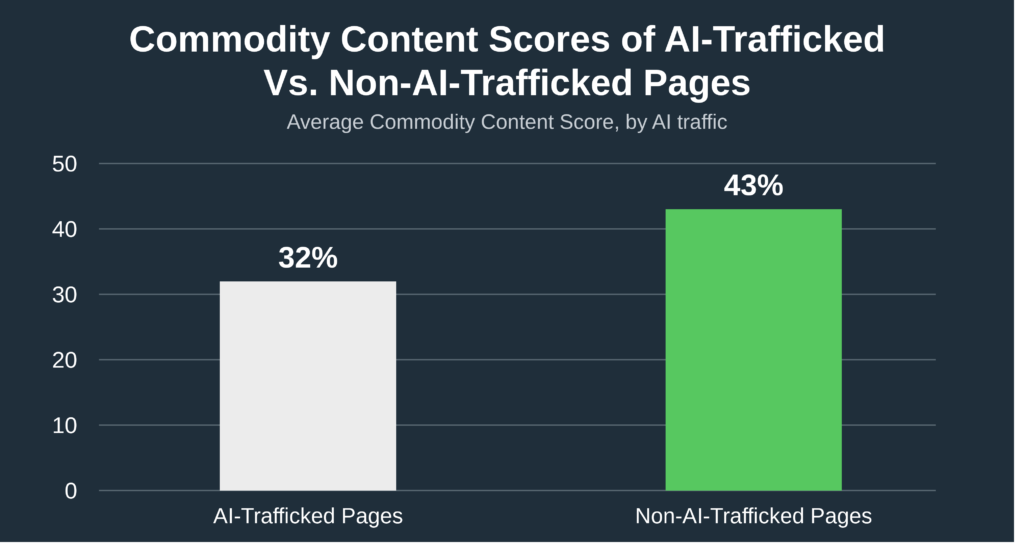
Next we set out to examine whether content with AI traffic on average contained more commodity content than pages without AI traffic and we found exactly that.
We noted that on average of the pages we analyzed, pages without AI traffic had an average of 33.33% more commodity content than pages with AI traffic:
At the start, we found this relationship to be somewhat noisy and expected the relationship between commodity content scores and AI visibility to become much more pronounced at the chunking level. For example, a web page may have 75% commodity content, however, the 25% non-commodity topics are extremely popular and retrieved often.
Controlling for popularity and scoring individual chunks rather than whole pages should expose a stronger signal, which is the work we are doing now. Even with the noise, the page-level data still pointed one way: AI-trafficked pages carried less commodity content on average than pages with no AI traffic.
Our Study Signals Bad News For Explainer, Evergreen Content
Evergreen What Is/How-to content has long been a hallmark of SEO content efforts. But it was another area where we hit statistical significance, even on smaller samples. What Is/How-to content averaged 72% commodity content. AI-trafficked pages averaged 32%. Only about 7.89% of those explainer pages earned any AI traffic at all.
The takeaway is blunt: when a page restates what the model already knows, the model answers from memory and skips the citation.
Put differently, the commodity score doubles as an AI visibility forecast. The closer a page sits to what the model already knows, the smaller its window for retrieval.
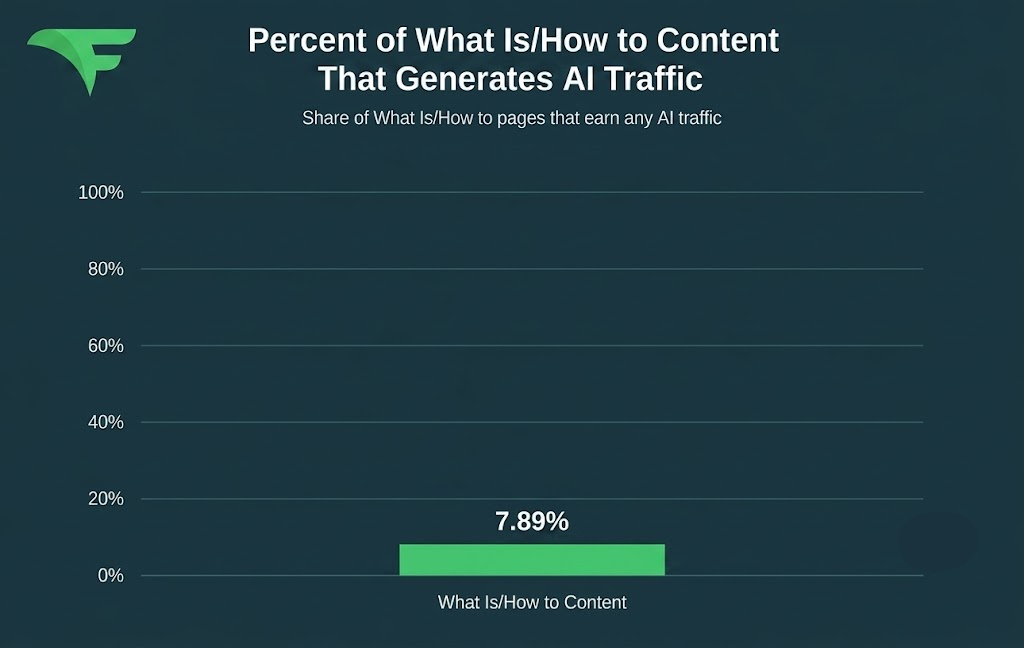
If your goal is AI citation, high-commodity explainer content works against you. When a page restates what the model already knows, the model answers from its own knowledge and the page rarely earns a citation.
Comparing Top AI Trafficked Pages Vs. Top Organic Trafficked Pages
When we compared the two cohorts directly, the top-performing organic (SEO) pages carried 84.6% more commodity content than the top AI-trafficked pages (95% CI: 37.8%–161.8%). The interval excludes zero, so the gap is statistically significant rather than noise — top AI-trafficked pages contain meaningfully less commodity content than top organic SEO articles.
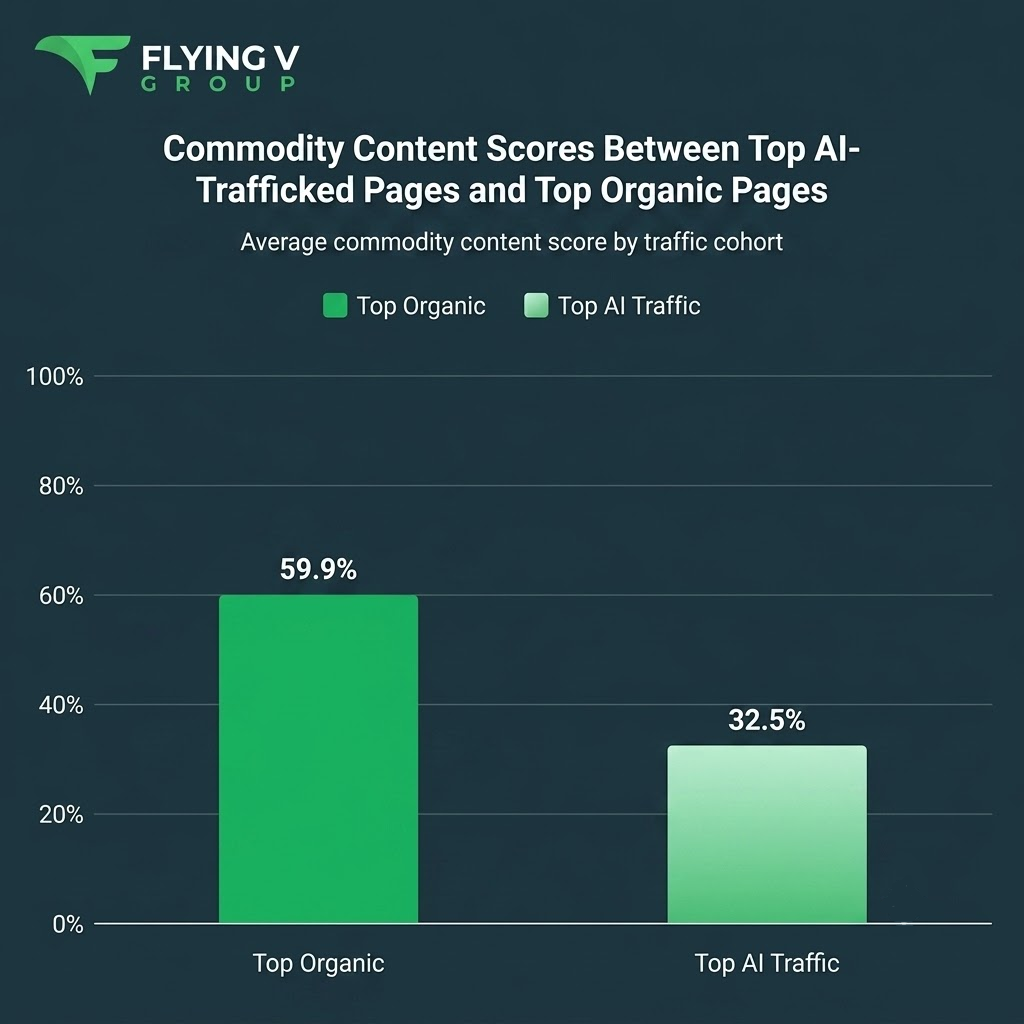
The most plausible explanation is demand-side: commodity topics are, almost by definition, the most-searched topics, so the pages that win organic traffic tend to cover well-trodden, high-volume subject matter. That same familiarity appears to work against a page in AI retrieval, where models lean toward content they internalized less completely.
This finding may also cut against Google’s stated narrative. Google has publicly maintained that the content winning in AI Overviews and AI Mode is largely the same content that performs in traditional organic search — that strong SEO fundamentals carry over to generative results. Our data suggests the opposite at the cohort level: the pages earning AI traffic look systematically different from the pages earning organic traffic, skewing toward lower-commodity, less-saturated material.
If our conclusion holds, it means that “good SEO content” and “good AI-retrieval content” are fundamentally not interchangeable.
This is consistent with an inverse relationship between commodity score and AI retrieval, but we treat that as directional rather than settled. A single cross-cohort comparison can’t fully separate the novelty effect from confounders like search demand and recency, and the confidence interval is wide. Additional data — and within-brand comparisons that hold the publisher constant — are needed before we characterize the relationship with confidence.
Limitations and Caveats
These results are directional, not definitive. While the difference between the cohorts clears statistical significance, this study represents an early slice of a much larger research effort, and a single comparison can only tell you so much. The confidence intervals are wide, which means the effects we’re seeing are real but their true magnitude is still loosely pinned down. As the dataset grows, expect those ranges to tighten and the estimates to move.
A few additional caveats deserve attention. This analysis relies heavily on cross-cohort comparisons, it is difficult to isolate the ‘novelty effect’ from confounding variables like search demand, page age, and recency. In particular, commodity topics naturally tend to generate the highest demand, creating an overlap that is incredibly challenging to untangle.
Additionally, the commodity score itself is non-deterministic and can drift by a few points between runs; individual page scores should therefore be treated as estimates rather than fixed metrics. Furthermore, because our sample is drawn exclusively from a small selection of large-publisher blogs, the findings may not generalize across all sites or verticals. Finally, this analysis relies heavily on correlation—nothing in this study proves that reducing commodity content directly causes a page to acquire more AI traffic.
In short, we shouldn’t overstate these results. The takeaway is narrow but actionable: the content currently winning AI traffic looks measurably different from what wins traditional organic search. These are early, preliminary findings—a strong signal worth exploring and a hypothesis worth testing further, rather than a definitive law of AI retrieval; that is to say, we will perform deeper, publisher-controlled analyses to truly validate these conclusions.
Give Our Commodity Content Tool a Try and Sign Up For Our Waitlist
The best way to understand commodity content is to measure it yourself.
Our Commodity Content Tool analyzes any URL and returns a score showing how saturated, replicated, and well-trodden a topic has become—the same metric used throughout this study. Compare your highest-performing organic pages against pages already earning AI visibility and see where they differ.
You may discover that your strongest search performers rely heavily on commodity content, while pages succeeding in AI systems contain more original information, expertise, or unique perspectives. Or you may find something entirely different in your own dataset.
We’re currently expanding access to the tool. Join the waitlist to be among the first to test your content, benchmark competitors, and uncover opportunities to create the kind of information AI systems are more likely to retrieve, cite, and learn from



