Today we were excited to share one of our first public-facing features: URL Checker. For a limited time, it will be free to use as part of an early beta release, and it will be officially rolling out in the near future.
This tool is still very much in beta, and that’s the point. We’re opening it up for a short window so we can collect real data and feedback. The techniques behind it still need to be validated, but even at this stage it’s already sparking interesting conversations.
In true SEO spirit, URL Checker takes inspiration from Google Search Console’s URL Inspect Tool. The idea is simple: drop in a URL and see whether ChatGPT is familiar with the information on that page.
We see membership inference and data attribution as core building blocks of the emerging field of Technical GEO.
Tools like URL Checker, along with others that are likely to follow, give website owners a way to understand how GPT and similar models are interacting with their sites at scale. They also create opportunities for brands to encourage models to train on their data through methods such as in-context probing.
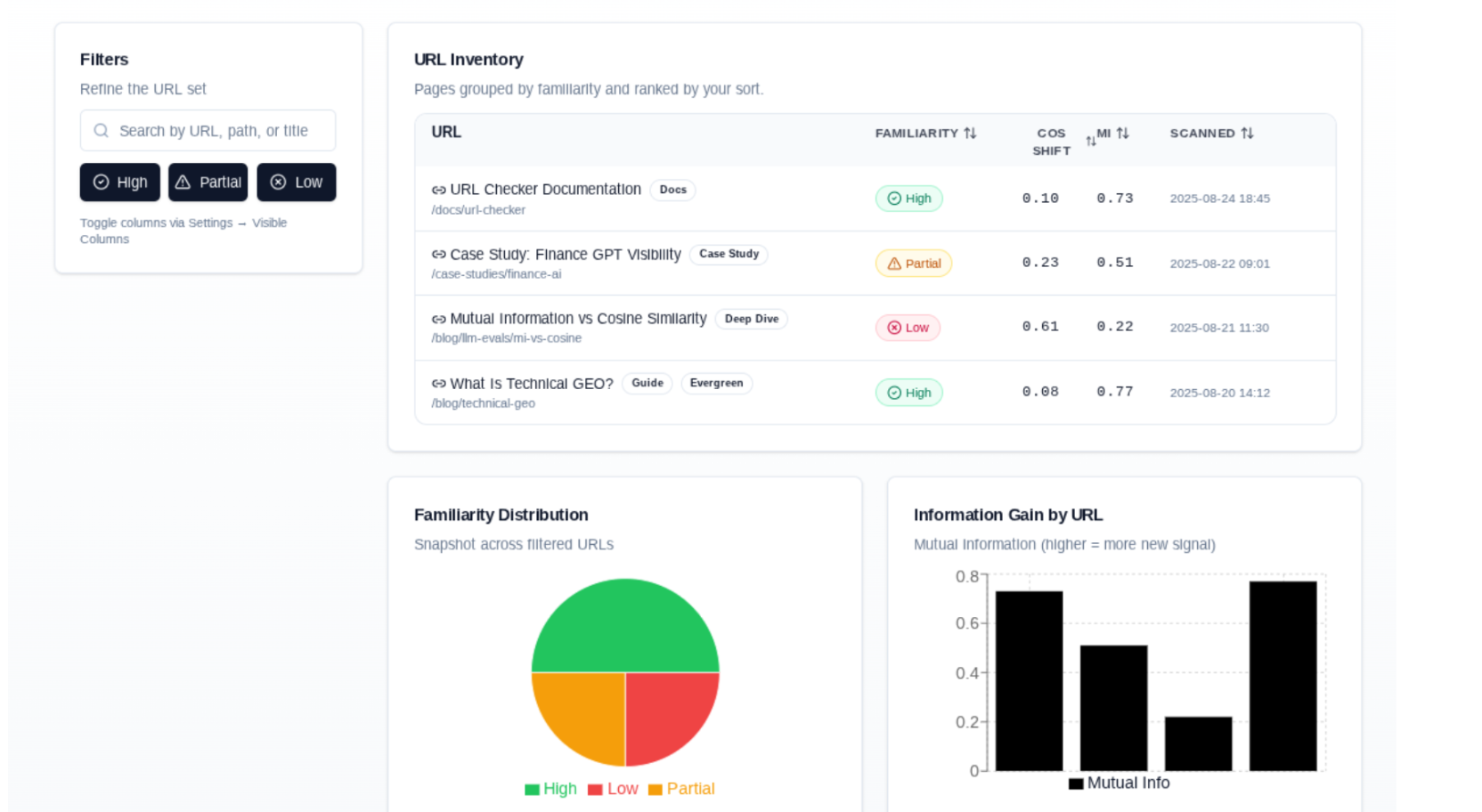
How URL Checker Works and Why It’s Important for Companies
URL Checker allows companies to identify whether or not ChatGPT is familiar with information contained within a web page (URL) using a combination of membership inference techniques and data attribution techniques.
The tool combines inference techniques with data attribution techniques. It works by scraping your web page and then allowing the LLM (in this case GPT-4) to generate three types of questions designed to gauge how familiar the model is with the content as well as generates as label for grounding:
A General Question: This question checks whether the model is broadly familiar with aspects of the content contained within the URL. On its own, this method is not reliable, since hallucinations or information pulled from other documents can produce similar outputs.
A Specific Question: This question is crafted so that it can only reasonably be answered by the document itself or by a very similar document. By doing this, we narrow the chance of false positives that might occur if we only asked general questions.
A True/False Question: This question helps further reduce false positives. By presenting a factual or incorrect statement and asking the model to classify it as true or false, we can spot hallucinations and reveal whether the model is genuinely familiar with the information in the document.
Generating Labels: Labels using in-context probing are generated in order to test blind answers and answers with added document context (answers without added context and answers with added context). Labels represent what the answer to questions SHOULD be and allows us to test if the model can answer questions correctly without added context and whether or not added context met label predictions.
To take this a step further, we apply mutual information statistical measures at the token level. By setting semantic thresholds, much like cosine similarity, we can identify how much information overlap exists between the outputs.
Higher mutual information implies greater document or knowledge familiarity, and it allows us to measure how much additional information was injected into the model’s response once the document was included in the context window.
Finally, we add a qualitative layer by prompting GPT-4 to classify its answers into one of three inference states:
High Familiarity: The model appears highly familiar with the content in the web page, and its responses reflect the information accurately and consistently.
Partial Familiarity: The model shows some knowledge of the content, possibly due to overlap with training data or because the content was updated but still shares key elements with earlier versions it may have trained on.
Low Familiarity: The model does not appear familiar with the information contained in the document or URL being analyzed.
There are, of course, limitations. Results may vary based on prompt structure, the inherent randomness of model outputs (temperature), and the model’s ability to paraphrase.
However, by keeping prompts consistent and answers tightly scoped, this method can has the potential to provide strong signals of whether a model is familiar with the information in a web page.
For companies investing in Technical GEO (Generative Engine Optimization), URL Checker offers critical visibility into how LLMs interact with their content. This makes it possible to diagnose technical issues and improve the chances of membership inclusion.
Precedents For Our Approach Within The Literature: In Context Probing
Although our approach is novel in how it combines techniques, many of its foundations build on precedents established in the literature.
The comparison of model outputs is grounded in principles from in-context probing and its observed connection to gradient-based attribution methods such as influence functions.
In-context probing is a technique used to examine what information a language model actually relies on when performing a task. Instead of fine-tuning or inspecting gradients, researchers insert carefully selected examples or definitions into the model’s prompt and then measure how the outputs or hidden states change.
By comparing the model’s behavior with and without certain contextual cues, in-context probing reveals whether knowledge comes from training data, the provided context, or a combination of the two.
This makes it a lightweight, black-box method for attributing model behavior and assessing data influence without requiring direct access to the model’s internal parameters.
Example of In-Context Probing From the Literature
To highlight the effectiveness of in-context probing, we can look at the research paper “On the Feasibility of In-Context Probing for Data Attribution.”
This study explores how in-context probing can serve as a practical approach for tracing the influence of training data, offering insights into both the opportunities and limitations of this method.

Although the ideas behind ICP can seem complex, the basic concept is simple. The model is asked questions or given instructions, then provided with additional in-context information.
Its outputs are compared to labels (a grounding truth), and from these comparisons, researchers can estimate how strongly specific examples or subsets of data influence the model’s behavior.
What makes this approach significant, as highlighted in On the Feasibility of In-Context Probing for Data Attribution, is that it offers a more computationally efficient alternative to gradient-based methods such as influence functions.
By leveraging the model’s own internal capabilities for reasoning with context, ICP reduces the cost of large-scale data attribution while still correlating closely with traditional attribution techniques. In other words, the study demonstrates that in-context probing not only scales more feasibly but also provides a practical framework for understanding how training data shapes model outputs, bridging the gap between interpretability and efficiency. And this has a major impact on GEO because it allows us to game membership selections, IT’S A BIG DEAL!
Ultimately, the paper concludes showing that in context probing has similar efficacy and correlates with more computationally heavy methods such as influence functions that rely on gradients.
Thus, ICP has been shown to be useful for data attribution and membership selection, methods that can be extended into Technical GEO to allow us to understand how ChatGPT and other LLMs understand the information across our website.
Source: https://arxiv.org/pdf/2407.12259
What The Future of Technical GEO Looks Like
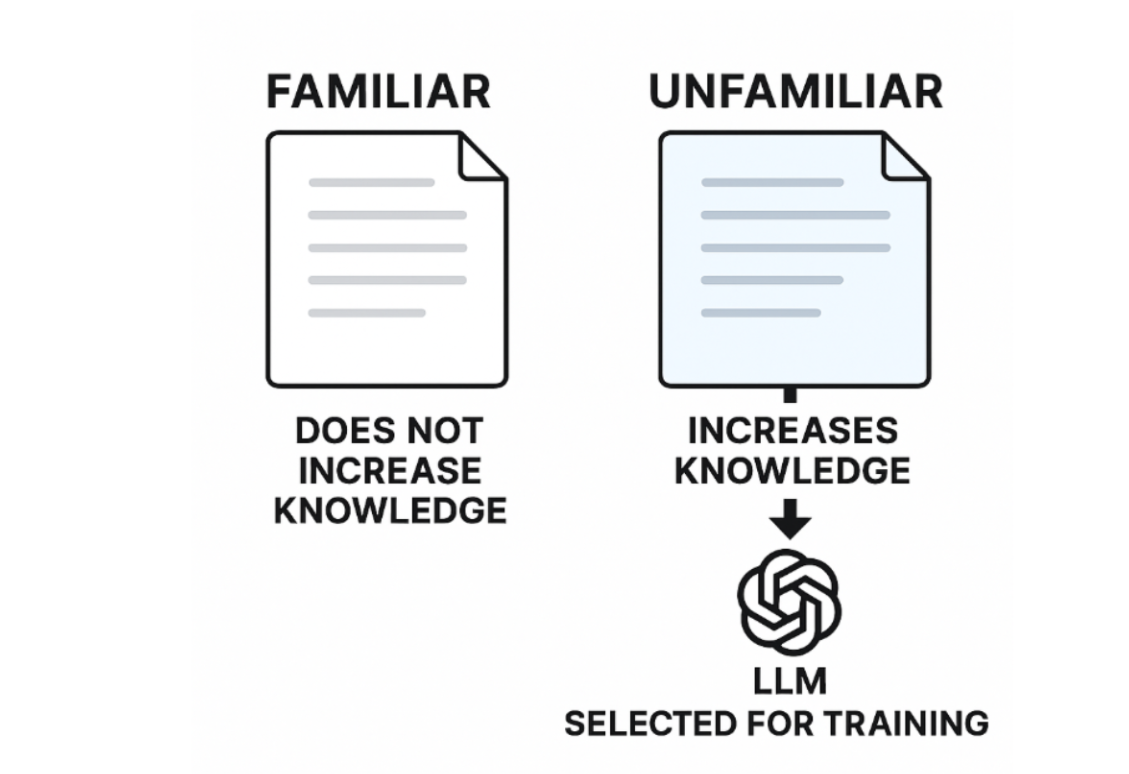
We believe that the future of technical GEO relies on categorizing your website based on model familiarity to drive decisions that influence tangible outcomes and looks something like this:
This will influence the future in two ways: allows companies to identify and classify content across their website to understand how GPT and other LLMs are familiar with content on your website AND allows companies to influence membership selection (whether or not ChatGPT will train on new content).
Understanding and Diagnosing Technical GEO Issues
First and foremost, if large swaths of your website fall into the “not familiar” category it denotes that this section of your website was largely omitted from training data which likely indicates either a crawling issue or content quality issue. These categorizations can help guide brands and understand where to focus their efforts.
Influencing Membership Selection
Unsurprisingly, this method can also be used to influence membership selection by which companies like ChatGPT identify types of content for inclusion that increases the model’s internal knowledge.
By net new content being placed in the “unfamiliar” section it teaches us the content is unique and adds to model knowledge thus likely increasing the probability it will be included in ChatGPT’s training data and that of other LLMs, however, this is not a guarantee, but it is objectively rooted in the types of techniques used by LLMs like ChatGPT:
For example, influence functions are often used to help with membership selection and in-context probing methods have been shown to well correlated with influence functions, by using URL checker and similar methods, brands can potentially optimise content for unfamiliarity meaning the content adds value to the model’s internal knowledge and increases the likelihood of membership selection and therefore influence on model output:
Validating Our Method and Our Upcoming Beta Release to Test URL Checker
It is important to stress that URL Checker is a black-box technique. Because we do not have access to model parameters, weights, or training sets, our approach relies on probing outputs and measuring differences when additional context is introduced. While this approach has strong precedents in the literature—such as influence functions and in-context probing—it still requires systematic validation.
A critical part of this validation involves testing URL Checker not only in live, real-world settings, but also against publicly available LLM datasets and benchmarks. By doing so, we can ground our methodology in open data, measure accuracy against known information, and reduce the risk of overfitting conclusions to narrow test cases.
The upcoming beta release is designed with this dual goal in mind:
- Field Validation – Deploying URL Checker across a variety of industries, content types, and website structures to test how consistently it distinguishes between familiar and unfamiliar content.
- Dataset Validation – Running controlled experiments against public LLM benchmarks and datasets, allowing us to measure efficacy under transparent conditions and provide stronger confidence in results.
This two-pronged validation strategy ensures that URL Checker is not only theoretically sound but also practically reliable. Early adopters in the beta will gain visibility into how their content is interpreted by LLMs today, while also contributing to a broader research effort that strengthens Technical GEO as a field.
Join Our Waiting List Gets News & Updates on The Launch of GEOGenius
By joining our waiting list, you’ll be the first to gain early access to URL Checker updates, new Technical GEO tools, and exclusive insights into how generative engines like ChatGPT interact with your website. Stay ahead of the curve, shape the future of data attribution, and secure your advantage in the evolving landscape of Generative Engine Optimization.
Join the waiting list here.
Looking For Generative Engine Optimisation Services?
Flying V Group helps brands stay visible in the age of AI-driven discovery. With deep expertise in SEO and pioneering work in Generative Engine Optimization, we combine proven strategies with innovative tools like URL Checker to ensure your content is surfaced by search engines and generative models alike.
If you’re ready to future-proof your visibility and drive measurable growth, our team can help. Contact us today.


0 Comments